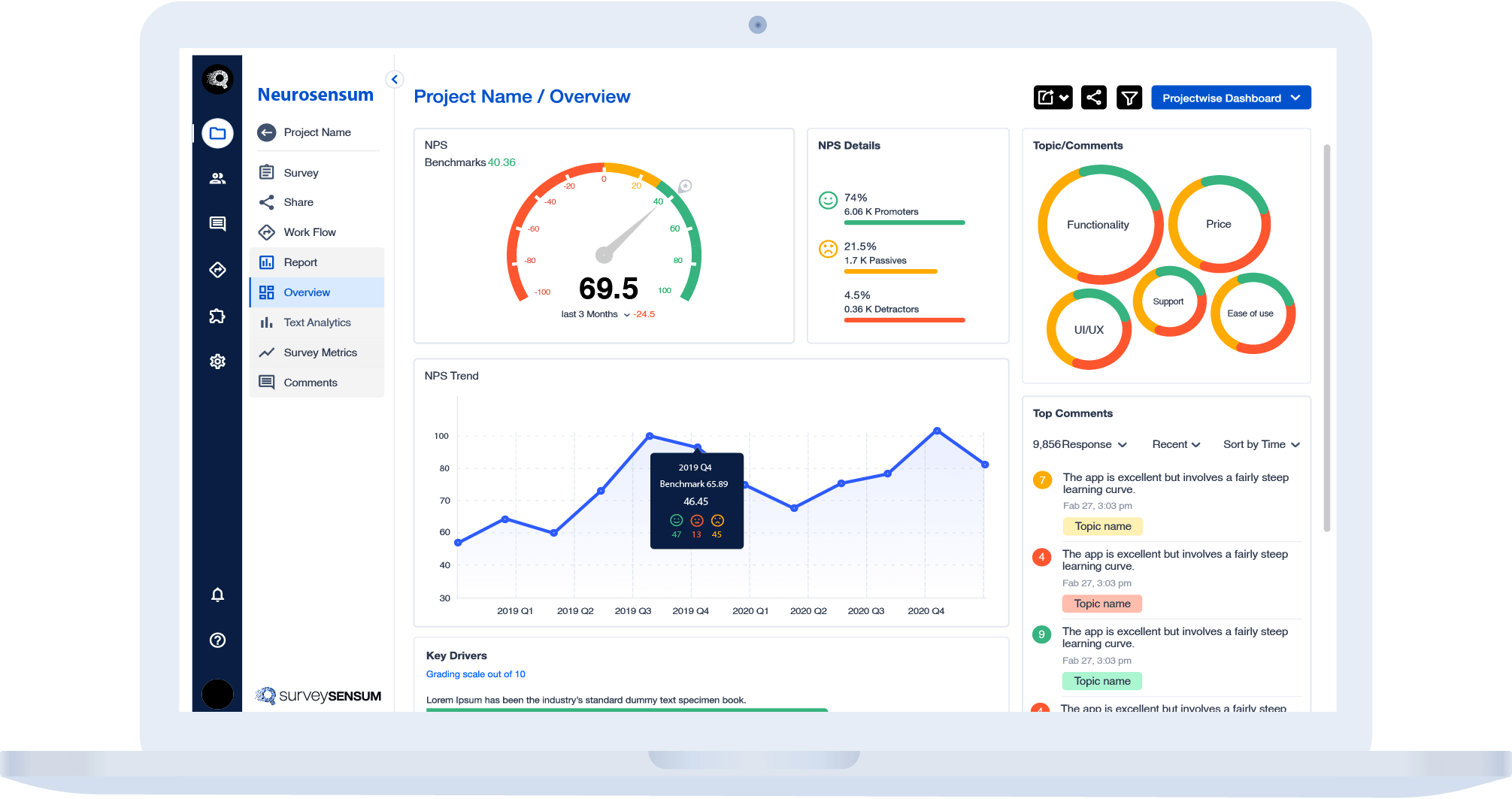
From emails, short text messages, to social media reviews, data is everywhere. However, these data are unstructured, and their true value lies in extracting actionable insights from them.
But what if all this data could be placed under a microscope, making the process of analyzing the nuances of unspoken messages, etc, seamless? Well, this is where Text Analytics Software comes in!
What is Text Analysis/Analytics?
Text analytics is the process of breaking down and extracting key actionable insights from clusters of unstructured textual data.
In customer experience management, textual data can take up several forms like survey responses, emails, support tickets, social media reviews, etc however, this data is unstructured and requires the process of text analysis to extract actionable insights from it.
It involves using techniques such as natural language processing, machine learning, and statistical analysis to identify patterns, sentiments, topics, and trends within written content. Text analytics can help you uncover two core questions:
- How are you performing on key CX metrics like NPS, CES, resolution time, etc?
- What’s bothering your customers that you are not aware of – like glitches in your software, etc?
Text analytics helps you answer these key questions, at scale, and help you remain connected with the voice of your customers.
But why is it important?
Why is Text Analytics Important?
What benefit can text analytics give to businesses that spend the time and resources to implement it?
Text analysis has become an important part of CX’s strategy, particularly for businesses looking for ways to improve their customer experience, optimize product development, and enhance employee engagement.
1. Understanding the Tone of Textual Content
Tweets with less than 140 characters can wreak more damage to a brand than a full-fledged press release or a page-long customer review. These brief comments often tell compelling stories about a brand’s customer service efficacy, making them crucial touchpoints for understanding customer sentiment.
Understanding the tone behind such comments is essential to gauging customer satisfaction levels. This is where text and sentiment analytics come into play. By sifting through both structured and unstructured data, these AI text analysis tools can determine whether the tone of the text is positive, negative, or neutral.
Using technologies like natural language processing (NLP) and machine learning, sentiment analysis provides a systematic way of extracting subjective information. It enables businesses to evaluate the user’s perspective about a product or service, offering actionable insights to improve customer experience.
2. Predict Trends and Customer Behaviour
Text analytics is not just retrospective; it is also predictive. By analyzing patterns in customer feedback, reviews, social media conversations, and online forums, businesses can uncover subtle shifts in consumer sentiment and behavior. These insights allow companies to anticipate needs, spot emerging trends, and adapt their strategies before competitors catch on.
For example, you can go through social media reviews and identify which competitor your customers are raving about currently, allowing your team to assess the feature’s relevance and decide if you should incorporate something similar into your offerings.
→ Read more about how text analytics can help you analyze, interpret, and help you take action on raw and unstructured social media reviews with social media text analytics!
3. Translation of Multilingual Customer Feedback
For any business spanning across the globe, there would be a diverse customer base that uses multiple languages for communication. Translating every byte of communication and analyzing it is a tough job, and it requires manual processes.
Text analytics helps cut through these linguistic barriers. It can translate unstructured text from all channels that customers are using.
Advanced machine learning models can enable the algorithm to decipher urban slang-heavy or acronym-heavy internet speech. In other words, text analysis can help you understand customer praise or ranting in any medium, in any language, and in plain language that your business can understand.
SurveySensum’s AI-enabled text analytics understands the nuanced feedback in the local languages to understand, detect, and analyze complex wordings and sentiments behind local languages. In short, it enables you to read between the lines and understand the nuances and complexities of local languages.
4. Understanding the “Why” Behind Customer Feedback
Quantitative data is essential for tracking performance – it shows metrics like sales trends, churn rates, and NPS. However, these numbers alone lack context. They tell you what is happening but leave the most important question unanswered: why?
This is where text analytics shines. By diving into unstructured data like customer feedback, survey responses, and reviews, text analytics uncovers the underlying reasons behind the numbers. It’s not just about identifying trends; it’s about understanding the emotions, frustrations, and motivations driving customer behavior.
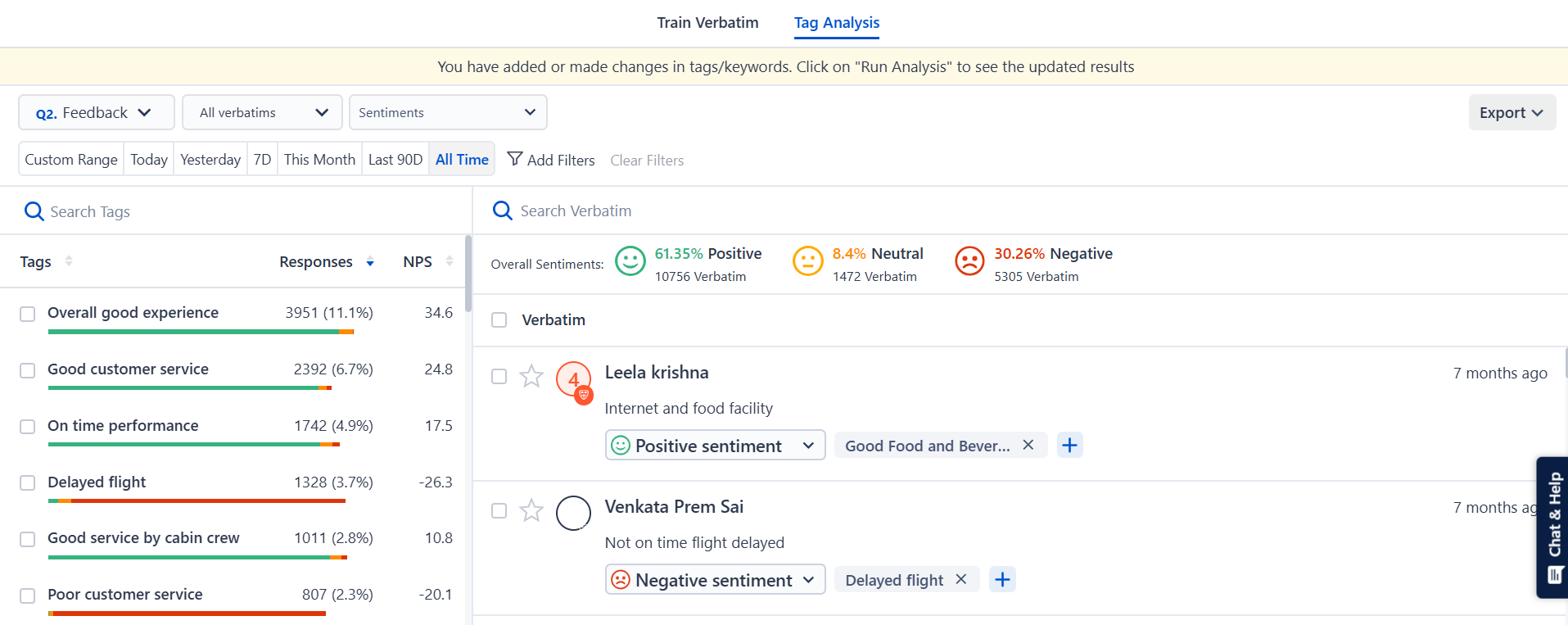
With SurveySensum’s text analysis software, you can sift through mountains of feedback in seconds to identify recurring issues and trends and go a step further – quickly spot themes, understand the “why” behind each feedback, gauge overall sentiment from open-ended feedback, and act in real-time.
SurveySensum leverages AI and NLP to provide unparalleled insights from open-text responses. Gain clarity, take action, and elevate your customer experience – get started today!
Free Forever • No Feature Limitation • No Credit Card Required • Sign Up For Free ![]()
Now, let’s understand how text analytics work.
How Does Text Analytics Work?
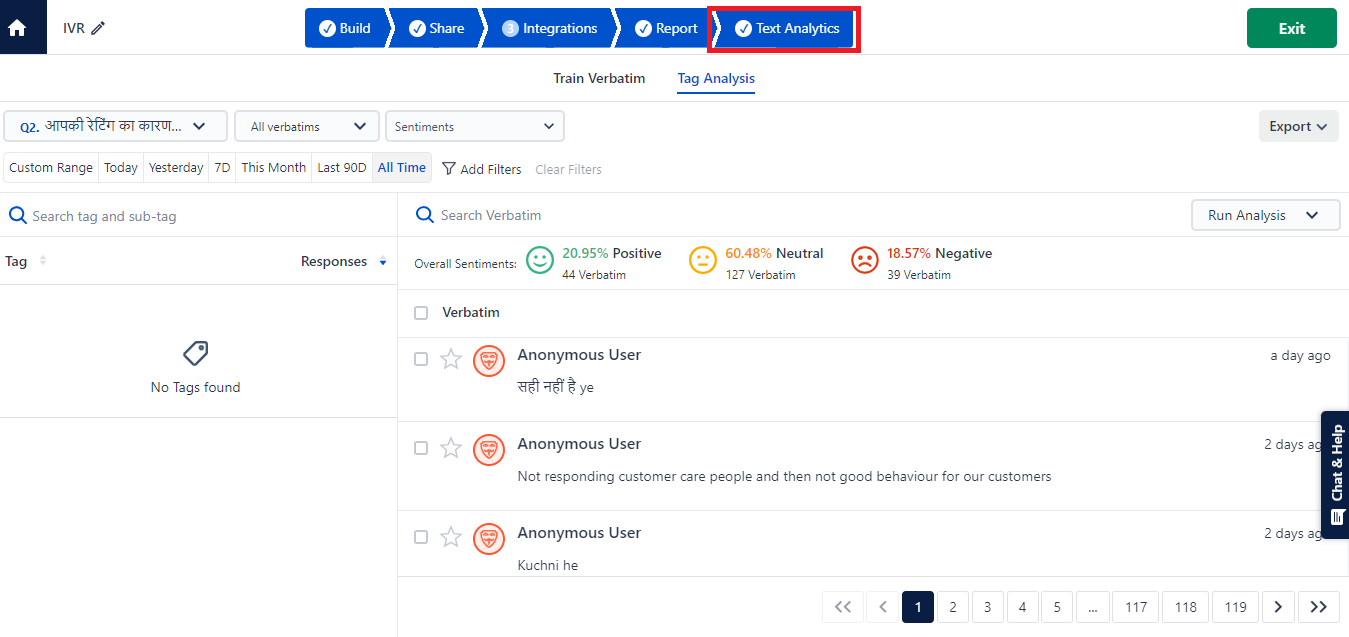
The process of text and sentiment analysis involves steps like language identification, word spotting, text categorization, etc – each step adds significant value and deep analysis for the overall process. Let’s now discuss each step.
1. Language Identification
The first technical step in text analytics is identifying the language of the text data. This is particularly important when dealing with a global dataset containing multiple languages. Language identification helps ensure that the correct linguistic rules and tools are applied during the analysis. For instance, distinguishing between English, Spanish, or French allows the system to choose the right algorithms for processing the text.
2. Word Spotting
Word spotting, also known as keyword spotting, is a technique used to identify specific words that represent the core meaning of a sentence. The assumption is that if a particular word is present, the entire sentence revolves around that word.
Let’s see how word spotting can be used to categorize the NPS Score responses to an NPS survey.

As you can see SurveySensum’s text analytics helps spot the word “experience” in every feedback and the system assumes that the sentence is about the overall customer experience. Similarly, the mention of the word “loved it” leads to the assumption that the sentence is about a good overall experience with the airline.
3. Tokenization
Tokenization is the process of breaking down text into smaller units called tokens, which typically correspond to words or phrases. By breaking text into individual tokens, the system can analyze each word’s meaning and its relationship with other words.
For example, with SurveySensum’s text analytics software, unstructured feedback is broken down into smaller relevant units to analyze each word’s meaning and overall emotion.
4. Chunking
Chunking refers to grouping tokens (words) into meaningful units, or “chunks,” based on grammatical categories such as noun phrases, verb phrases, and adjective phrases.

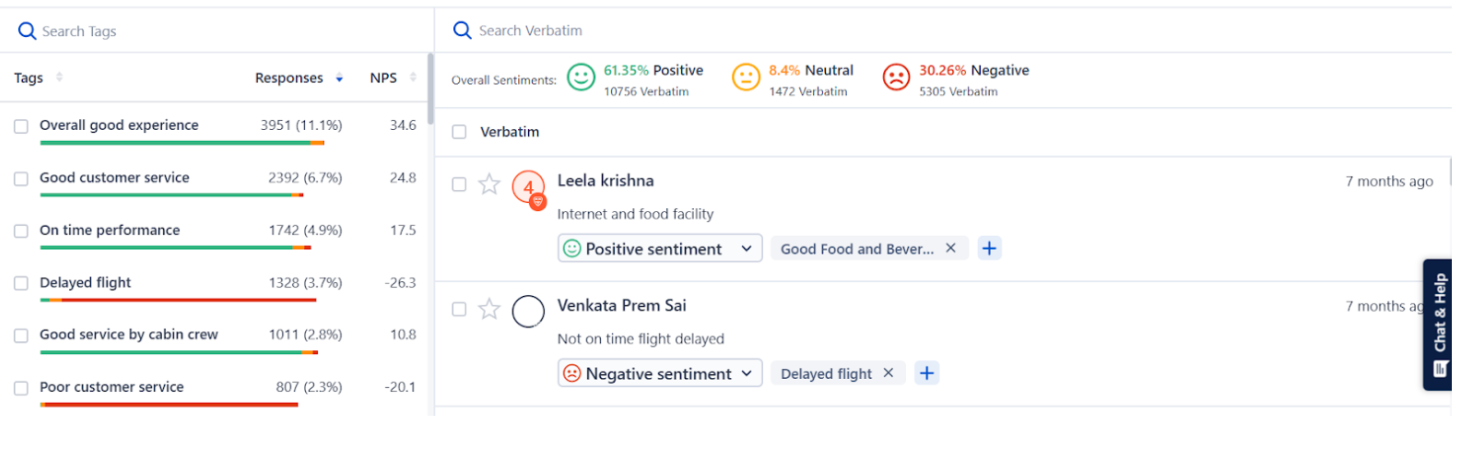
For example, as shown in the above image, the sentence “Staff (Ground and On-board)” is not clear enough. However, SurveySensum’s text analytics breaks down the sentence into “good service by cabin crew” and “good ground services” which becomes more meaningful and easy to decipher. Chunking helps the system understand the relationships between different parts of speech, improving the accuracy of text interpretation.
5. Sentiment Analysis
Sentiment analysis identifies and categorizes the sentiment expressed in the text—whether it’s positive, negative, or neutral. This step helps businesses gauge customer satisfaction, detect potential issues, and measure overall sentiment toward products, services, or brands.

For instance, a review with the phrase “I love this product” would be classified as positive, while “The service was terrible” would be classified as negative.
6. Topic Modeling
Topic modeling analyzes the text to identify underlying themes or topics. By using techniques like Latent Dirichlet Allocation (LDA), topic modeling groups words that frequently appear together, allowing the system to discover hidden topics within large datasets. This step can help businesses identify trending themes or popular issues among customers.
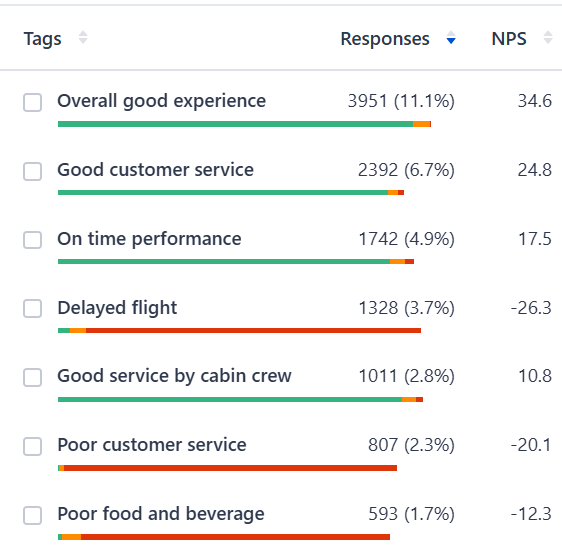
For example, with SurveySensum’s text analytics repeated keywords are grouped together and the percentage of their repetition is also shown, helping businesses to identify recurring themes and customer pain points and take prioritized action.
7. Data Visualization and Reporting
Finally, the results of the text analytics process are typically visualized in reports or dashboards to provide businesses with clear, actionable insights. These insights can include sentiment trends, the most frequently mentioned topics, customer pain points, or emerging market trends. Visualization makes it easier for decision-makers to interpret complex text data and act on it quickly.
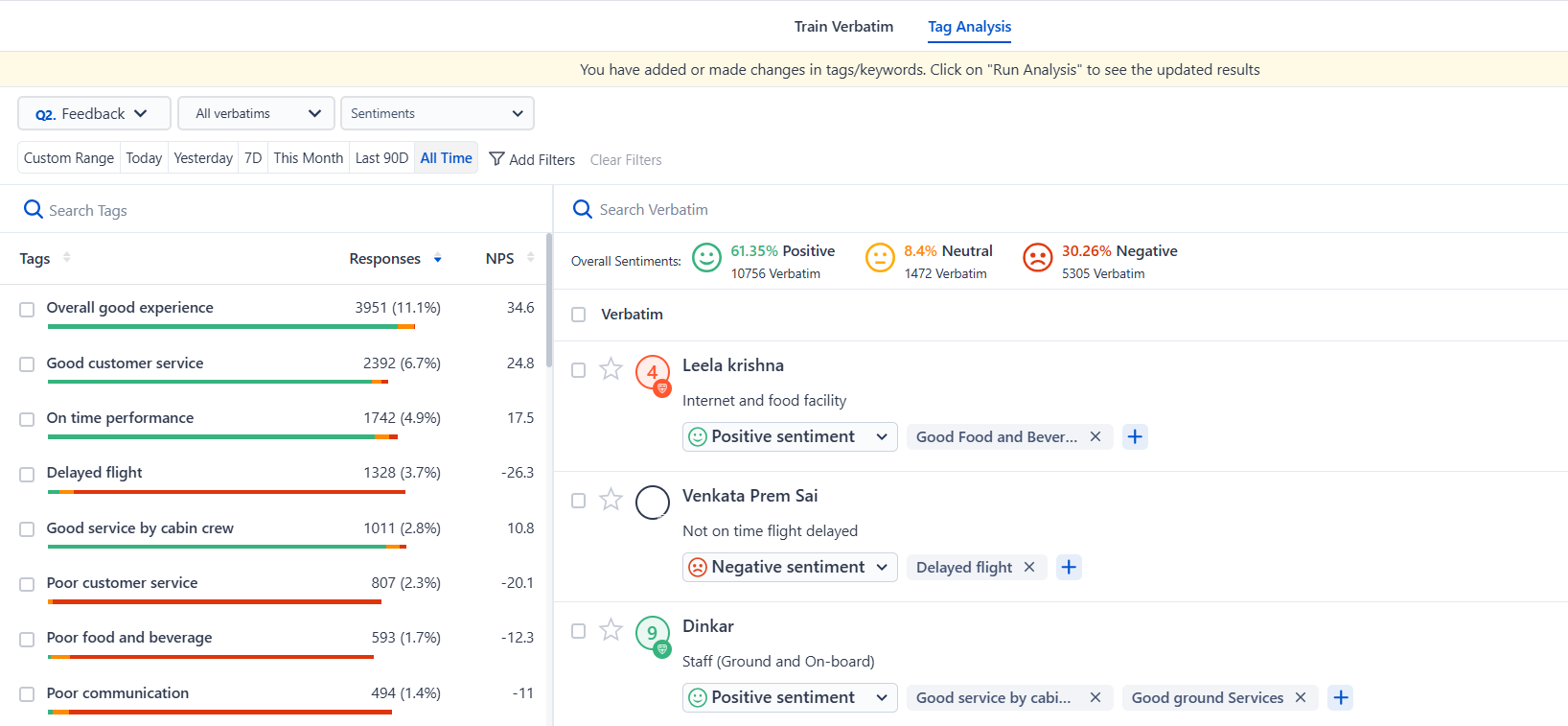
SurveySensum’s text analytics categorizes responses into different themes or topics, such as in-flight experience, food review, etc., while sentiment analysis evaluates the sentiment (positive, negative, neutral) associated with each topic, offering insights into areas where customers are particularly satisfied or dissatisfied.
→ Understand the difference between text analytics vs sentiment analysis to determine which analysis will suit you the best!
Understanding the workings of text analytics is only beneficial when it is applied effectively to drive business decisions and CX strategies. So, let’s look at some applications of text analytics in business.
Business Applications of Text Analysis
Given the various approaches and benefits of text analytics, how is text analytics applied in business? Here are some of the business applications of text analytics.
Improving Overall Customer Experience
- Sentiment Analysis: Understand customer emotions in real-time by analyzing reviews, surveys, or support ticket comments. For instance, discovering that a high percentage of customers use words like “frustrating” in complaints about delivery delays can prompt immediate process improvements.
- Churn Prediction: Track negative sentiment trends in customer interactions to predict and address dissatisfaction before customers leave. For instance, language like “thinking of canceling” in interactions can trigger proactive retention efforts.
- Cross-sell/Up sell: It is possible to identify opportunities for cross-selling or upselling by combining operational data like CLV or customer spending with renewal dates and analysis of topics like reward, incentive, etc.
Enhancing Customer Support for Service Teams
- Automated Query Clustering: Text analytics can group similar queries into categories, allowing support teams to prioritize and address issues more efficiently. For instance, common questions like “How do I reset my password?” can be routed to automated responders, reducing agent workload.
- Workflow Optimization: Categorizing and prioritizing tickets automatically reduces response times and ensures that complex issues are routed to the right teams. This results in a more streamlined and satisfying support experience.
Driving Targeted Advertising for Marketers
- Customer Insights: Text analytics extracts preferences, behaviors, and sentiments from sources like search queries, reviews, and social media. These insights allow businesses to design ads that resonate with specific audiences.
- Real-Time Trend Analysis: By tracking trending topics and keywords, businesses can tailor ad campaigns to align with current customer interests. For example, if “sustainability” is trending, ads highlighting eco-friendly practices can be prioritized.
- Improved ROI: Targeted ads based on accurate text analysis ensure better engagement, higher click-through rates, and more conversions, maximizing return on investment.
Optimizing Recruitment for Human Resources
- Resume Screening: Using NLP, text analytics tools can scan resumes and match qualifications to job requirements. For example, keywords like “project management” or “data analysis” can be automatically flagged to shortlist suitable candidates.
- Bias Reduction: Automating resume screening reduces unconscious bias, ensuring fair evaluation of candidates based on their skills and experience rather than subjective factors.
- Efficiency Boost: Text analytics significantly reduces the time spent on manual resume reviews, enabling recruiters to focus on interviews and relationship-building.
Enhancing Brand Experience for Marketers
- Social Media Monitoring: Analyze mentions of your brand across platforms like Twitter, Instagram, and forums to understand customer perceptions. For example, discovering positive trends during a product launch can confirm campaign success.
- Reputation Management: Monitor for potential PR crises by detecting spikes in negative mentions. Automated alerts for terms like “scam” or “disappointing” can prompt immediate corrective actions.
- Competitor Benchmarking: Compare customer perceptions of your brand to competitors by analyzing mentions, reviews, and feedback. Identifying areas where competitors are praised can highlight opportunities for improvement.
Driving Product Development for Tech Teams
- New Feature Request: Sift through customer suggestions from support tickets, forums, or reviews to identify in-demand features. For example, many users requesting a “dark mode” feature can guide development priorities.
- Market Research: Analyze online discussions, such as Reddit or Quora threads, to uncover emerging trends and preferences in the industry. For instance, customers frequently mentioning “sustainability” can guide eco-friendly product innovations.
- New Launch: Analyze textual feedback from beta testers to refine new features. Comments like “intuitive” or “needs improvement” can be categorized to highlight strengths and weaknesses.
- Product Usage: Key insights on what features to invest further can be extracted by analyzing warranty data to increase usage, reduce service costs, etc.
Improving Overall Employee Experience For Human Resources
- Engagement Surveys: Analyze responses to open-ended questions in employee surveys to identify and analyze key drivers of engagement or dissatisfaction. For example, phrases like “lack of growth opportunities” can signal improvement areas.
- Retention Analysis: Examine exit interviews or survey responses to identify common reasons for attrition, such as “lack of recognition” or “work-life balance issues.”
- Performance Feedback Analysis: Extract actionable insights from peer or manager feedback in appraisals. For example, identifying frequent mentions of “collaboration issues” can lead to focused training initiatives.
Text Analysis for NPS Improvement: Unlocking Customer Sentiment
Since the days of the Industrial Revolution, businesses have been trying hard to find out how customers feel about their products or surveys. The search reached some kind of conclusion in the last decade when the Net Promoter Score was introduced.
NPS aims to collect customer feedback in a concise form with a single question. “How likely are you to recommend this product/brand/service to your friends or colleagues?” depending on the response rate, the business can decide how well they are faring in serving customers.
Text analytics, combined with NPS data, can help businesses unlock valuable insights from open-ended responses and provide a deeper understanding of customer sentiment. Here’s how text analytics can be leveraged to enhance NPS and drive improvement in customer experience:
1. Analyze All Survey Responses – No Sampling Required!
Picture this: you’ve launched an NPS survey and received thousands of responses. Exciting, right? But reading through each response manually isn’t just tedious—it’s impractical. Sampling seems like an option, but it risks overlooking critical feedback that might reveal serious flaws.
Enter text analytics, your secret weapon for processing every single response. By automating the analysis, you ensure that nothing slips through the cracks. This approach provides a near-accurate breakdown of promoters, passives, and detractors, offering a full-spectrum view of customer sentiment.
Pro Tip: Use text analytics to highlight recurring phrases or words in detractor comments to pinpoint specific pain points.
2. Categorize Feedback into Themes
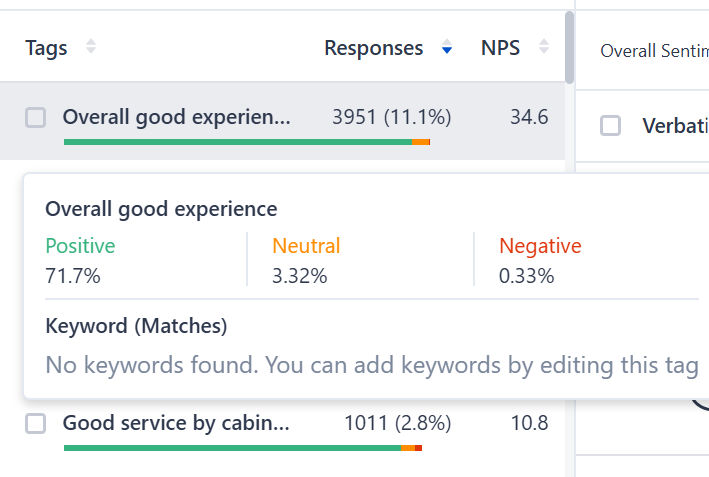
NPS already categorizes customers into promoters, passives, and detractors, but what if you could go deeper? To truly understand what drives loyalty – or dissatisfaction – you need to uncover patterns in their responses.
With text analytics, you can identify recurring themes. For example:
- Promoters: Are they raving about your product’s ease of use or excellent customer service?
- Passives: What’s keeping them on the fence?
- Detractors: Are they dissatisfied with pricing, quality, or support?
By categorizing feedback into actionable themes, you can focus on areas that need improvement while amplifying your strengths.
Scenario: If passives often mention “long delivery times,” you know exactly where to direct your attention.
From chaos to clarity – SurveySensum’s AI capabilities categorize open-ended survey responses into clear themes, giving you instant access to customer insights on key areas like pricing, support, and product features!
Free Forever • No Feature Limitation • No Credit Card Required • Sign Up For Free ![]()
3. Data to Craft a Marketing Story
Take a cue from iconic brands like Apple, Airbnb, and Amazon—they don’t just sell products; they sell stories. Apple is synonymous with user privacy. Airbnb is celebrated for its unique travel experiences. What’s your brand’s unique story?
Text analytics can help you discover the narrative hidden in your NPS data.
For instance:
- Are promoters praising your product’s eco-friendliness? Highlight it in your campaigns.
- Do customers appreciate your hassle-free returns process? Build that into your value proposition.
These insights can fuel marketing campaigns that resonate deeply with your audience, enhancing your brand image and loyalty.
Fun Fact: Airbnb’s “Belong Anywhere” campaign drew heavily on user feedback about the joy of unique and personal travel experiences.
So, that’s all about what is happening in text analysis, but what does the future hold for text analysis? Let’s see.
The Future of Text Analytics
The future of text analytics is poised for exciting advancements, driven by technological innovation and the increasing need for businesses to extract actionable insights from customer feedback, social media conversations, reviews, and more.
Here are some key trends shaping the future of text analytics:
- Real-Time Text Analytics: Supports analysis of textual data in real-time, enabling quick responses to customer feedback, reviews, and social media mentions. This results in proactive issue resolution and improved customer satisfaction.
- Multilingual and Cross-Cultural Insights: Enhanced capabilities to analyze feedback in multiple languages and dialects, providing global insights and allowing businesses to personalize strategies based on regional and cultural nuances.
- Integration with Voice and Visual Data: Combining text analytics with voice recognition (speech-to-text) and image recognition for a holistic view of customer sentiment.
- Predictive Analytics and Customer Journey Mapping: Using AI to predict future customer behavior based on historical text data. This will enable companies to offer personalized experiences and anticipate customer needs, improving satisfaction and loyalty.
In a Nutshell
Text analytics has been around for a long time. Ever since the days of cave drawings, mankind has been trying to decipher the hidden meaning in texts and symbols.
In today’s world, text analytics has leapfrogged to a new dimension. It is used to dig out the hidden meaning in text messages and content that users create in their daily lives.
That search for meaning also enables businesses to understand their customers better and serve them better. To sum it up, text analytics is a must-have tool for businesses that want to read between the lines of what their customers are writing about them.
Struggling to make sense of scattered feedback? With SurveySensum’s AI-powered text analytics, automatically categorize customer responses into meaningful themes and focus on solving real problems in real-time!
Free Forever • No Feature Limitation • No Credit Card Required • Sign Up For Free ![]()
FAQs on Text Analytics
1. What do you mean by text analytics?
Text analytics is the process of extracting meaningful insights from unstructured data using computer systems and techniques like machine learning, NLP and statistical analysis to extract patterns, trends, and valuable information from text sources such as emails, surveys, reviews, and social media posts.
2. Is text analytics part of AI?
Yes, text analytics is a part of AI. It uses AI technologies like machine learning, natural language processing, and deep learning to analyze and interpret human language in a way that computers can understand.
3. What is the purpose of text analysis?
The main purpose of text analysis is to organize, understand, and draw insights from large volumes of text data. It helps businesses and researchers uncover hidden patterns, monitor customer opinions, improve decision-making, and automate tasks like customer support.
4. Why is text analytics important in business?
Text analytics is crucial for businesses because it enables them to better understand their customers, improve products and services, detect emerging trends, manage brand reputation, and make data-driven decisions. By analyzing customer feedback, support tickets, and social media mentions, businesses can gain a competitive advantage and enhance customer experience.
5. What is call center text analytics?
Call Center Text Analytics is the process of analyzing text-based data — like customer call transcripts, chat logs, and emails — to uncover insights about customer sentiment, behavior, and common issues. It helps call centers improve service quality, identify trends, and make data-driven decisions to enhance the customer experience.
6. What is text analytics for health?
Text Analytics for Health involves using NLP and AI to extract valuable information from unstructured medical text, such as clinical notes, patient records, and doctor-patient conversations.
7. What is conversation analytics?
Conversation Analytics is the practice of capturing and analyzing spoken or written interactions between businesses and customers. By examining phone calls, chats, emails, and social media conversations, companies can gain insights into customer needs, emotions, satisfaction levels, and sales opportunities, helping them improve communication strategies and overall customer experience.
8. What is cross-tabulation?
Cross-tabulation (or crosstab) is a method used in data analysis to compare the relationship between two or more variables in a table format. It helps researchers and businesses identify patterns, correlations, and trends by showing how different groups respond differently to certain questions or situations, making it easier to spot actionable insights.
9. What is key driver analysis?
Key driver analysis is a statistical technique used to determine which factors have the biggest impact on a particular outcome, like customer satisfaction or loyalty. By identifying the “key drivers,” businesses can focus their efforts on the areas that will make the most significant difference in improving results.
Take your business insights to the next level with advanced text analytics solutions. Start exploring SurveySensum today and see how actionable insights can drive smarter decisions and greater success!
Free Forever • No Feature Limitation • No Credit Card Required • Sign Up For Free ![]()